第2章 渲染流水线
2.1 什么是渲染流水线
渲染流水线中3个概念阶段:应用阶段,几何阶段,光栅化阶段
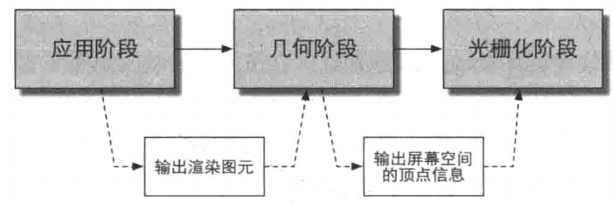
应用阶段
由CPU负责,此阶段我们需要设置好每个模型的渲染状态,渲染状态包括但不限于它的材质,纹理以及使用的Shader等。此阶段最重要的输出是渲染所需的几何信息——渲染图元(rendering primitives)。
渲染图元可以是点、线、三角面等。渲染图元将被传递到下一阶段——几何阶段。
几何阶段
这一阶段通常在GPU上进行,决定需要绘制的图元是什么,如何绘制它们,在哪绘制它们。
这阶段负责和应用阶段传过来的每个 渲染图元 打交道,进行逐顶点、逐多边形的操作,可细分为更小的流水线阶段。
几何阶段的重要任务就是把顶点坐标转换到屏幕空间中,交给光栅器进行处理。此阶段对渲染图元进行处理后,会输出屏幕空间的二维顶点坐标,每个顶点对应的深度值,着色等相关信息,并传到下一阶段——光栅化阶段
光栅化阶段
此阶段也是在GPU上进行,使用上阶段传递过来的数据来产生屏幕像素,并渲染出最终的图像。
主要任务是决定每个渲染图元中的哪些像素应该绘制到屏幕上。需要对上一阶段得到的逐顶点数据(如纹理坐标,顶点颜色等)进行插值,然后进行逐像素处理。
2.2 CPU和GPU之间的通信
渲染流水线的起点是CPU,即应用阶段,应用阶段大概分为3个阶段:
- 把数据加载到显存。
- 设置渲染状态
- 调用Draw Call
2.2.1 把数据加载到显存
渲染数据先从硬盘加载到内存中,然后网格和纹理等数据又被加载到显存中。
数据加载到显存后,内存中的数据就能移除了,但有些数据我们可能还需要访问它(例如,我们可能需要CPU访问网格数据来进行碰撞检测),此时数据就暂时不需要移除出内存。
2.2.2 设置渲染状态
渲染状态定义了场景中网格如何被渲染,例如使用哪个顶点着色器,哪个片元着色器,使用什么材质等。假如不更改渲染状态,所有网格将使用同一种渲染状态,所以看起来不同网格外观像是使用了同一种材质。
2.2.3 调用Draw Call
Draw Call是一个命令,由CPU发起,由GPU接收。
当给定一个Draw Call时,GPU会根据 渲染状态 和 所有顶点数据 来进行计算,最终输出到屏幕显示出像素。
2.3 GPU流水线
2.3.1 概述
概念阶段中,几何阶段和光栅化阶段,开发者的控制权限有限。这两个阶段又可分为更小的流水线阶段,由GPU来实现这些流水阶段,每个阶段GPU提供了不同的 可配置性 或 可编程性。
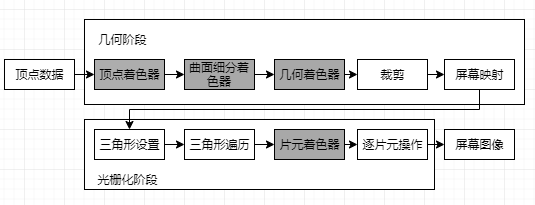
几何阶段:
- 输入:顶点数据,由应用阶段加载到显存中,再由Draw Call指定。
- 顶点着色器(Vertex Shader):完全可编程,常用于顶点空间变换,顶点着色。
- 曲面细分着色器(Tessellation Shader):可选着色器,用于细分图元。
- 几何着色器(Geometry Shader):可选着色器,用于执行逐图元着色操作,或产生更多图元。
- 裁剪(Clipping):可配置,将不再摄像机视野内的顶点裁剪掉,剔除某些三角图元的面片。
- 屏幕映射(Screen Mapping):不可配置不可编程,负责将图元的坐标转换到屏幕坐标系中。
光栅化阶段:
- 三角形设置(Triangle Setup):固定函数阶段
- 三角形遍历(Triangle Traversal):固定函数阶段
- 片元着色器(Fragment Shader):完全可编程,用于实现逐片元的着色操作。
- 逐片元操作(Per-Fragment Operations):不可编程,但有很高可配性,可以执行很多重要操作,如:修改颜色,深度缓冲,进行混合等。
2.3.2 顶点着色器
处理单位:顶点着色器是流水线的第一阶段,输入来自CUP。处理单位是顶点,输入的每个顶点都会调用一次顶点着色器。
速度快:顶点着色器本身不会创建或销毁任何顶点,也无法知道顶点与顶点之间的关系(也就是说我们无法知道两个顶点是否属于同一个三角网格)。也正因为这种相互独立性,GPU可以利用本身的特性并行化处理每个顶点,这样这一阶段处理速度会很快。
主要工作:坐标变换、逐顶底光照
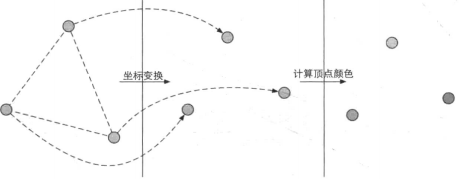
- 坐标变换:对顶点的坐标进行某种变换。顶点着色器可在这一步改变顶点的位置,这样可以实现一些我们需要的效果,如模拟水面,布料等。
- 顶点着色器必须完成的工作:把顶点坐标从模拟空间转换到齐次裁剪空间。
2.3.3 裁剪
我们的场景可能非常大,但是摄像机视野是有限的,场景中不在我们视野中的物体完全没必要渲染,裁剪就是为了这个目的被提出来的。
一个图元跟摄像机视野的关系:
完全在视野内:图元继续传到下一阶段
部分在视野内:进行裁剪,保留在视野内部分,裁剪掉视野外部分。
完全在视野外:不会继续向下传递,因为不需要被渲染
这个阶段不可编程,无法通过程序来控制裁剪的过程,而是硬件固定操作。但我们可以自定义应该裁剪操作来对这一步进行配置。
2.3.4 屏幕映射
这一阶段的输入坐标仍然是三维坐标。
任务:把每个图元的x和y坐标转换到屏幕坐标系下,屏幕坐标系是一个二维坐标系,它和我们用于显示画面的分辨率有很大关系。
屏幕映射得到的屏幕坐标决定了这个顶点对应屏幕上哪个像素以及距离这个像素有多远。
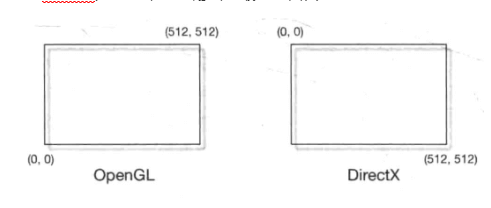
注意:屏幕坐标系在OpenGL和DirectX之间存在差异
- OpenGL把屏幕左下角作为坐标原点(0, 0)
- DirectX把屏幕左上角作为坐标原点(0, 0)
2.3.5 三角形设置
从这开始,进入光栅化阶段。上阶段输出的信息是屏幕坐标系下的顶点位置以及和它们相关的额外信息(如:深度值,法线方向,视角方向等)
光栅化重要目标:
- 计算每个图元覆盖了哪些像素
- 为这些像素计算它们的颜色
三角形设置 是光栅化流水线的一个个阶段。这一阶段会计算光栅化一个三角网格所需的信息。
上一阶段输出的都是三角网格的顶点,我们得到的是三角网格每条边的两个端点。想要得到整个三角网格对像素的覆盖情况,我们就必须计算每条边上的像素坐标。
为了计算边界像素的坐标信息,我们就需要得到三角形边界的表示方式,这样一个计算三角网格表示数据的过程就叫三角形设置。
2.3.6 三角形遍历
此阶段会检查每个像素是否被一个三角网格覆盖,如果被覆盖,会生成一个片元。
找哪些像素被三角网格覆盖的过程就是 三角形遍历 ,也称为 扫描变换。
三角形遍历阶段会根据上一阶段的计算结果来判断一个三角网格覆盖了哪些像素,并使用三角网格3个顶点的顶点信息对整个覆盖区域的像素进行插值。
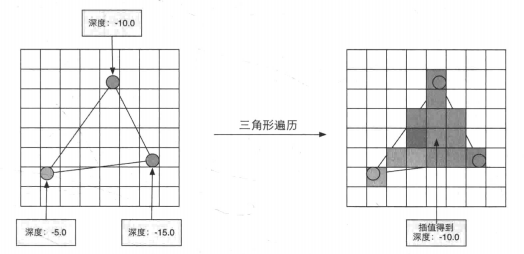
此阶段输出的是一个片元序列,需要注意的是,一个片云不是真正意义上的像素,而是包含了多种状态的集合,这些状态用于计算每个像素的最终颜色。这些状态包括但不限于屏幕坐标,深度信息等,以及其他几何阶段输出的顶点信息,如法线、纹理坐标等。
2.3.7 片元着色器
片元着色器是非常重要的可编程着色器阶段。
前面的光栅化阶段实际不会影响屏幕上每个像素的颜色值,而是会产生一系列的数据信息,用来表述一个三角网格是怎么覆盖每个像素的。每个片元就负责存储这样一系列数据。真正对像素产生影响的阶段是——逐片元操作。
输入:上阶段对顶点信息插值得到的结果
输出: 一个或多个颜色值
这一阶段可以完成很多重要的渲染技术,其中最重要的技术之一就是 纹理采样 ,为了在片元着色器中进行纹理采样,我们通常会在顶点着色器阶段输出每个顶点对应的纹理坐标,然后经过光栅化阶段对三角网格的3个顶点对应的纹理坐标进行插值,就可以得到其覆盖的片元纹理坐标了。
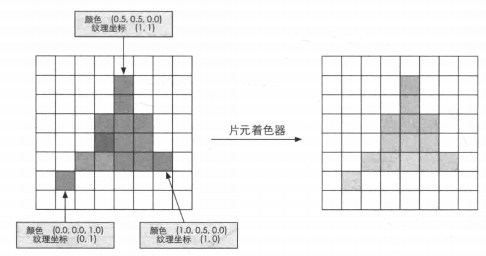
局限性:仅可以影响单个片元,执行片元着色器时,它不可以将自己的任何结果发送给它的邻居。
2.3.8 逐片元操作
此阶段高度可配置性,我们可以设置每一步的操作细节。
渲染流水线最后阶段,在OpenGL中和DirectX中有不同叫法:
- OpenGL中:逐片元操作
- DirectX中:输出合并阶段
主要任务:
- 决定每个片元的可见性,涉及很多测试工作,如深度测试,模板测试等。
- 如果一个片元通过了所有的测试,就需要把这个片元的颜色值和已经存储在颜色缓冲区中的颜色进行合并,或者说混合。
下面是逐片元操作所做的操作:

下面是模板测试和深度测试的简化流程图:
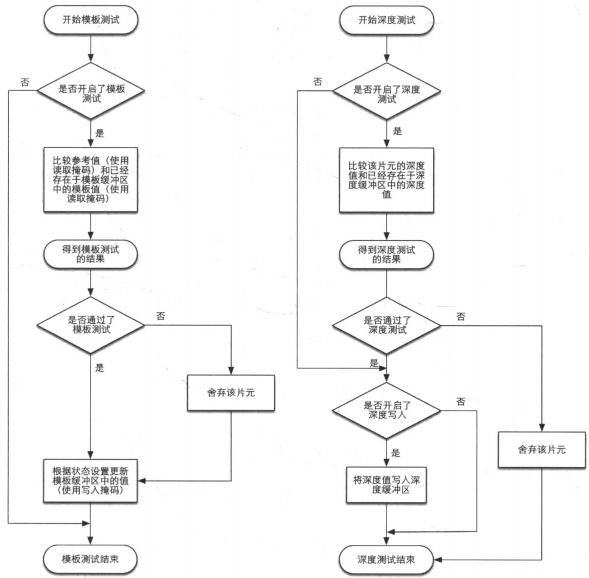
模板测试
如果开启了模板测试,GPU会首先读取(使用读取掩码)模板缓冲区中该片元位置的模板值,然后将该值和读取到的参考值进行比较,比较函数可以由开发者指定。如果一个片元没有通过测试,该片元将会被舍弃。不管一个片元有没有通过模板测试,我们都可以根据模板测试和深度测试结果来修改模板缓冲区。
深度测试
通过了模板检测的片元,会进行下一个测试——深度测试。
如果开启了深度测试,GPU会把该片元的深度和已经存在于深度缓冲区中的深度进行比较。这个比较函数也可以由开发者设置。
和模板测试测试不同,一个片元如果没有通过深度测试,它没有权利更改深度缓冲区中的值。
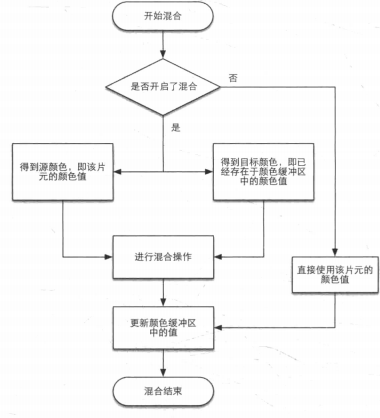
混合
对于不透明物体,开发者可以关闭混合操作,这样片元着色器计算得到的颜色就会直接覆盖颜色缓冲区中的像素值
对于半透明物体,我们就需要使用混合操作来让这个物体看起来是透明的。
当模型的图元经过上面层层计算和测试后,就会显示到我们的屏幕上,我们的屏幕显示的是颜色缓冲区中的颜色值。但是为了避免我们看到那些正在进行光栅化的图元,GUP会使用双重缓冲(Double Buffering)的策略。这意味着,对场景的渲染是在幕后发生的,即在后置缓冲区中。一旦场景已经被渲染到后置缓冲中,GUP会交换后置缓冲区和前置缓冲区中的内容,而前置缓冲区是之前显示在屏幕上的图像,由此保证我们看到的画面是连续的。
2.4 容易困惑的地方
2.4.1 什么是OpenGL/DirextX
OpenGL/DirextX是图像应用编程接口,这些接口用于渲染二维或三维图形。可以说这些接口架起了上层应用程序和底层GPU的沟通桥梁。一个应用程序向这些接口发送渲染命令,而这些接口会依次向显卡驱动发送渲染命令,【显卡驱动】是真正知道如何跟GPU通信的角色,它们负责将OpenGL/DirextX的函数翻译成GPU能听懂的语言,同时它们也负责把纹理等数据转换成GPU所支持的格式。
2.4.2 什么是HLSL、GLSL、CG
都是着色语言(Shading Language)
- HLSL:(Hight Level Shading Language),DirectX
- GLSL:(OpenGL Shading Language),OpenGL
- CG:(C for Graphic), NVIDIA
2.4.3 什么是Draw Call
Draw Call就是CPU调用图像编程接口, 以命令GPU进行渲染的操作。
Draw Call造成性能问题的元凶是CPU而非GPU。
问题一:GPU 和CPU如何并行工作
为了提高效率,CPU和GPU需要并行工作,实现方式:使用命令缓冲区(Command Buffer)
命令缓冲区包含一个命令队列,由CPU向其中添加命令,GPU负责读取命令,添加跟读取过程都是相互独立的,这样就实现了并行工作。
命令缓冲区的命令很多种,Draw Call是其中一种,其他命令还有改变渲染状态等(例如改变使用的着色器,使用不同纹理等)。
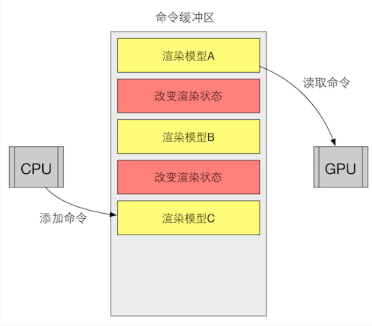
往往改变渲染状态命令更加耗时。
问题二. 为什么Draw Call多了会影响帧率
每次调用Draw Call之前,CPU需要向GPU发送很多内容,包括数据,状态和命令等。这一阶段CPU需要完成很多工作,例如检查渲染状态等。一旦CPU完成了这些准备工作,CPU就可以开始本次的渲染。
GPU渲染能力很强,速度往往快于CPU提交命令的速度,如果Draw Call数量太多,CPU就会把大量时间花费在提交Draw Clall上,造成CPU过载。
问题三. 如何减少Draw Call
可以使用批处理(bathching)方法,把小的DrawCall合并成一个大的DrawCall
游戏开发过程中,为减少Draw Call的开销,需注意:
- 避免使用大量的很小的网格,当不可避免地使用很小的网格结构时,考虑是否可以合并它们。
- 避免使用过多的材质。尽量在不同网格之间共用同一个材质。